Dynamic radiance field reconstruction methods aim to model the time-varying structure and appearance of a dynamic scene. Existing methods, however, assume that accurate camera poses can be reliably estimated by Structure from Motion (SfM) algorithms. These methods, thus, are unreliable as SfM algorithms often fail or produce erroneous poses on challenging videos with highly dynamic objects, poorly textured surfaces, and rotating camera motion. We address this robustness issue by jointly estimating the static and dynamic radiance fields along with the camera parameters (poses and focal length). We demonstrate the robustness of our approach via extensive quantitative and qualitative experiments. Our results show favorable performance over the state-of-the-art dynamic view synthesis methods.
RoDynRF addresses the robustness issue of SfM algorithms by jointly estimating the static and dynamic radiance fields along with the camera parameters (poses and focal length).
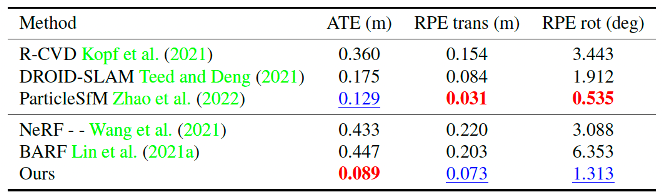

Our method performs significantly better than existing NeRF-based pose estimation methods. Note that our method also performs favorably against existing learning-based visual odometry methods.
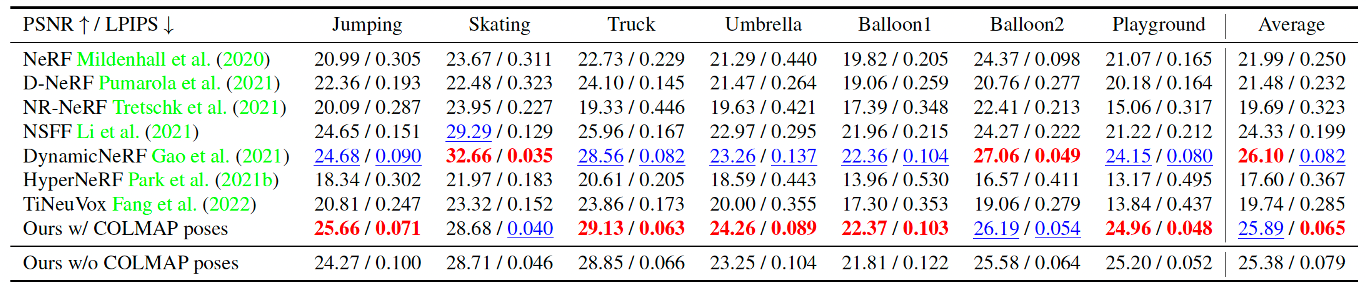

Our method performs favorably against state-of-the-art methods. Furthermore, even without COLMAP poses, our method can still achieve results comparable with the ones using COLMAP poses.
Our method reconstructs consistent geometry.
@inproceedings{liu2023robust,
author = {Liu, Yu-Lun and Gao, Chen and Meuleman, Andreas and Tseng, Hung-Yu and Saraf, Ayush and Kim, Changil and Chuang, Yung-Yu and Kopf, Johannes and Huang, Jia-Bin},
title = {Robust Dynamic Radiance Fields},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year = {2023}
}